
本文介绍项目部署,我们将创建一个云端在线的项目后端应用程序。
托管选项
对于Django项目,我们可以选择托管在VPS或PaaS中。VPS需要更多的部署技能,而PaaS则很简单。PaaS有多种产品,我们选择Heroku。

git管理
如果没有安装git,就去git-scm.com下载安装。
git是每个程序员的必备技能,一般过程是:
- 初始化库,“git init”, 这样就在当前目录创建了git存储库,git存储库类似数据库,管理我们项目的快照。当我们项目有修改时,我们可以保存快照到存储库中。后续可以随时查看保存的快照,查看当时的状态,等等。
- 将修改加到暂存库,“git add . ”。稍后可以提交给git存储库。
- 提交,“git commit -m ‘<一些提交的说明信息>'”。
- 查看提交,”git log –online”。
初识Heroku
使用Heroku需要一个账号,如果没有,就花几分钟注册一个,这是免费的。然后谷歌搜索”heroku cli“找到Heroku Cli命令行工具并根据说明安装好,我们通过命令行工具管理我们的应用程序。验证一下。
heroku --version登录heroku。常规情况是不加 -i ,打开网页进行验证。但国内环境,用代理会出现IP地址不匹配,不代理又访问不了验证页面,所以使用命令行加 -i 验证方法。由于2023年2月开始heroku 必须使用多因子认证,命令行验证仅是邮箱和密码将是无效的,所以要用API key作为密码登录。API key可以访问这里获取:
https://dashboard.heroku.com/account
heroku login -i创建Heroku应用
在heroku-cli创建一个应用kelemibuy-prod,注意名称必须是唯一的。
heroku create kelemibuy-prodhttps://kelemibuy-prod.herokuapp.com/https://git.heroku.com/kelemibuy-prod.git
创建完成后,heroku给了我们一个托管应用的网站,以及一个远程git存储库。这样我们在本地和远程都有了一个存储库,当我们准备部署时,我们将本地的存储库推送到远端存储库,heroku会监视该存储库,发现变更后就自动进行部署,非常简单。
现在正式环境有域名了,我们需要在settings.prod里添加ALLOWED_HOST。
ALLOWED_HOSTS = ['kelemibuy-prod.herokuapp.com']设置环境变量
在settings.prod中,我们看到SECRET需要从环境变量SECRET_KEY读取,但首先我们得生成一个SECRET_KEY,有很多在线工具可以用,我们访问这个网站:
https:djecrety.ir
生成一个SECRET_KEY,然后到heroku设置该环境变量,注意环境变量的值用单引号包起来。
heroku config:set SECRET_KEY=')4527d^#($@bpdbhf5nqy69vf5c)0)6560m08za^u@s)2k%y5*'
我们再来设置之前说过的环境变量DJANGO_SETTINGS_MODULE,设置为正式环境的配置值。
heroku config:set DJANGO_SETTINGS_MODULE=storefront.settings.prod创建Procfile
Procfile告诉Heroku如何启动我们的应用程序。在项目根目录新建文件Procfile,这是 process file的简写,注意第一个P大写,且不带扩展名。
- release。表示项目发布时执行的命令,我们写上迁移数据库命令。有些人不喜欢自动迁移migrate数据库,也可以不写,后面我们会介绍如何手动在heroku上迁移数据库。
- web。项目需要设置web处理程序,我们用的gunicorn
- worker。作为web的附加部分,我们需要启动celery来处理后台工作。
release: python manage.py migrateweb: gunicorn storefront.wsgiworker: celery -A storefront worker
置备MYSQL数据库
访问https://dashboard.heroku.com/,给我们的项目添加mysql组件,heroku有很多合作的组件可以选择,对于mysql我们选择:ClearDB MySQL,免费的计划就好。这样就完成mysql的置备。
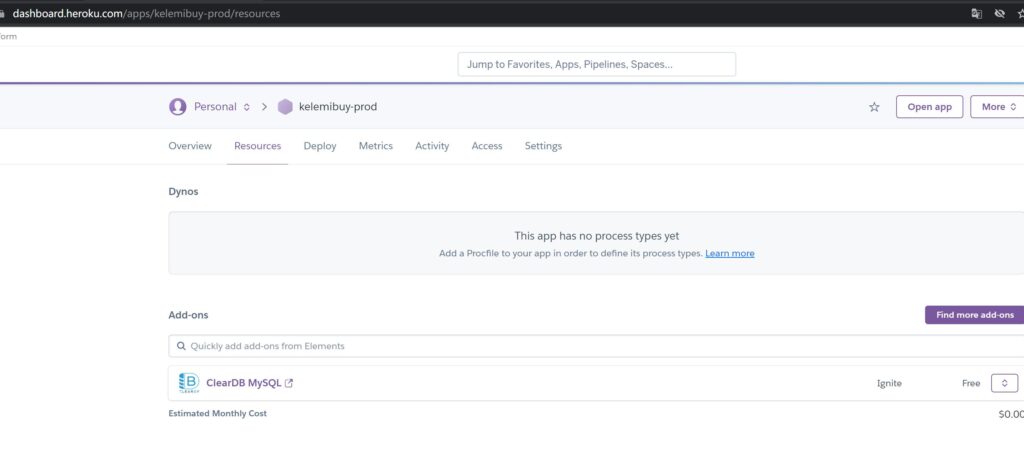
回到控制台,查看heroku配置:
heroku config我们看到我们已增加了一个环境变量CLEARDB_DATABASE_URL。
CLEARDB_DATABASE_URL: mysql://b876a727b78a30:3923251b@us-cdbr-east-06.cleardb.net/heroku_649c5c7d9a7ce70?reconnect=trueDJANGO_SETTINGS_MODULE: storefront.settings.prodSECRET_KEY: )4527d^#($@bpdbhf5nqy69vf5c)0)6560m08za^u@s)2k%y5*
我们添加一个环境变量 DATABASE_URL,值就是新增的环境变量删除问号及后面这小块的内容。问号后的URL部分在django用不到,有些其他语言项目会用到。
heroku config:set DATABASE_URL=mysql://b876a727b78a30:3923251b@us-cdbr-east-06.cleardb.net/heroku_649c5c7d9a7ce70现在我们要设置我们的生产环境的数据库为这个数据库链接。在开发环境中,数据库相关信息比如用户密码是明确指定的,但在正式环境中,我们使用是数据库链接,为此我们需要安装dj-database-url库。
pipenv install dj-database-url再在storefront.settings.prod模块里添加DATABASES,dj_database_url的config函数获取环境变量DATABASE_URL的值,并自动解释成数据库连接的详细信息,而DATABASE_URL环境变量前面我们已设好了。
import dj_database_url...DATABASES = {'default': dj_database_url.config()}
置备Redis实例
之前我们用了两个Redis数据库一个1,一个是2。在heroku上当然也可以置备二个,但会增加成本。但实际上我们没必要将消息中介和缓存分开放不同的Redis数据库,因为它不是关系数据库,就是键值对,完全可以合二为1,除非有很强的理由一定要分开。
这里,我们就使用同一个Redis数据库。
同样访问https://dashboard.heroku.com/,添加Redis组件,比如Heroku Redis,这里用的是 Redis Enterprise Cloud。查看heroku config,发现已加了REDISCLOUD_URL环境变量。
...REDISCLOUD_URL: redis://default:WxJ0D4ekujdmEkZouwwe1B3kwAMcxHwG@redis-10614.c92.us-east-1-3.ec2.cloud.redislabs.com:10614...
接着我们将common.py里的关于redis配置的移到dev.py中。
CELERY_BROKER_URL = 'redis://localhost:6379/1'CACHES = {"default": {"BACKEND": "django_redis.cache.RedisCache","LOCATION": "redis://127.0.0.1:6379/2","TIMEOUT": 10*60,"OPTIONS": {"CLIENT_CLASS": "django_redis.client.DefaultClient",}}}
redis在prod.py中则改成刚在heroku生成的redis数据库。
REDIS_URL = os.environ['REDISCLOUD_URL']CELERY_BROKER_URL = REDIS_URLCACHES = {"default": {..."LOCATION": REDIS_URL,...}}
置备SMTP服务器
有不少SMTP服务器可以选择,这里选择Mailgun。同样在heroku上选择免费的我们添加到我们的项目中。
然后查看环境变量heroku config ,能看到SMTP服务器相关信息,包括用户密码等。
我们将 common.py的SMTP配置部分移到dev.py和prod.py,再将prod.py的STMP配置由获取的环境变量设置。
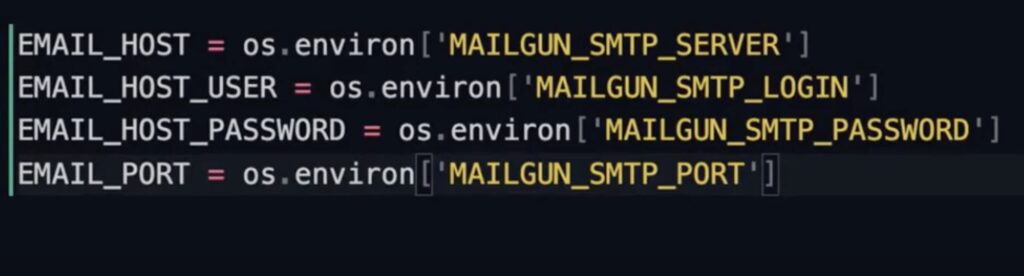
我们顺便将这句:
EMAIL_BACKEND = ‘django.core.mail.backends.smtp.EmailBackend’
去掉了,因为这是默认的,没必要明确出来。
部署应用程序
首先我们要将本地修改的加到暂存区,然后提交给本地存储库,这样我们的工作区就干净了,目前本地存储库是最新的commit和快照。
git add .git commit -m '...'
接着我们可以提交到远端heroku的存储库,该存储库我们之前创建的,也就是我们的应用程序。
先查看一下远端的存储库:git remote -vv
heroku https://git.heroku.com/kelemibuy-prod.git (fetch)heroku https://git.heroku.com/kelemibuy-prod.git (push)
然后再查下本地的分支:git branch
* master本地的分支默认就是master,有些机器或许是main。然后我们提交到heroku。
git push heroku master
传到heroku存储库后,heroku就会自动进行构建应用程序。我们观察发现有错误,在收集Silk的静态资产时出现错误,因为我们之前silk只安装在开发环境中,prod没装,我们重新安装下。
pipenv install django-silk
安装后再进行提交:
git add .git commit -m 'Install Silk as a dependency'
然后我们再提到heroku:
git push heroku master
等待完成部署即可。顺便说一句,在heroku使用Clear DB可能会有些诡异,可以考虑使用PostgreSQL,heroku对它支持最好也最健壮,也可以使用JawsDB MySQL。添加新的数据库后,只需更改下heroku的环境变量DATABASE_URL即可。
你可能好奇我们在heroku上部署的内容是怎么样的,可以使用:
heroku run bash这样就进入heroku的终端窗口,我们可以用 ls 查看项目目录,也可以使用exit命令退出。
我们再来创建超级用户,跟我们之前是一样的,只需加上 heroku run就行:
heroku run python manage.py createsuperuser
创建完毕后,然后打开heroku项目:
heroku open
这样就打开了我们的项目网站。我们查看是否正常,包括登录管理员后台确认刚建的管理员已生效。
https://kelemibuy-prod.herokuapp.com/
填充数据库
我们项目的store应用有一个management/commands目录结构,在其下有一个seed_db.py的python脚本,这个目录下的脚本能被manage.py读取执行。在heroku环境中,我们执行填充下:
heroku run python manage.py seed_db
执行完成后,我们访问heroku项目网站查看相关数据是否已填充,比如
https://kelemibuy-prod.herokuapp.com/store/products
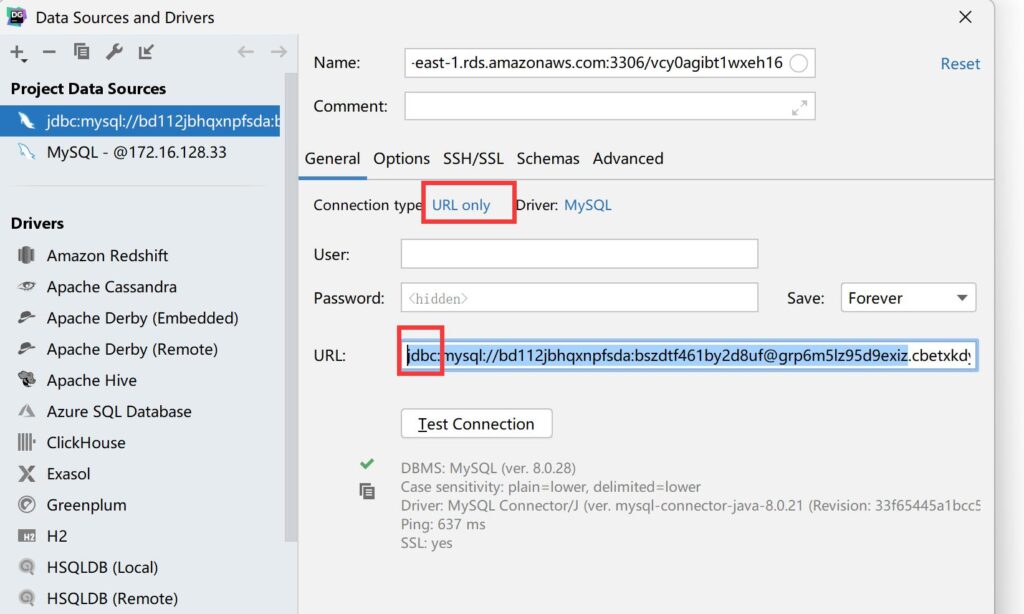
再一个,我们希望我们在heroku应用的数据库能使用DataGrip等数据库工具连接。首先获取DATABASE_URL:
heroku config:get DATABASE_URL
我们得到以mysql://开头的连接字符串,然后打开DataGrip,连接MySQL,选择连接类型为 URL only,在URL处保持前面的jdbc:,然后粘贴连接字符串,就可以打开heroku的数据库了。
容器化应用
我们要运行我们的应用,有一些服务要启动,比如MySQL,Redis,Celery,Smtp4Dev,Flower等等。每次我们运行应用时,都需要打开多个终端窗口,一个一个地启动服务,有点繁琐。另外,当一个程序员加入团队时,他也要安装这么多依赖,要是他的软件版本有些不同的话比如说MySQL,软件可能会呈现 不同的行为。这就需要Docker来协助了。
利用Docker,我们可以方便启动所有服务,更重要的是,我们能保证开发环境与正式环境完全一致。
打开前面下载的附件,在\Code\9- Deployment\Docker 下有四个文件,我们将其拖到项目根目录下。
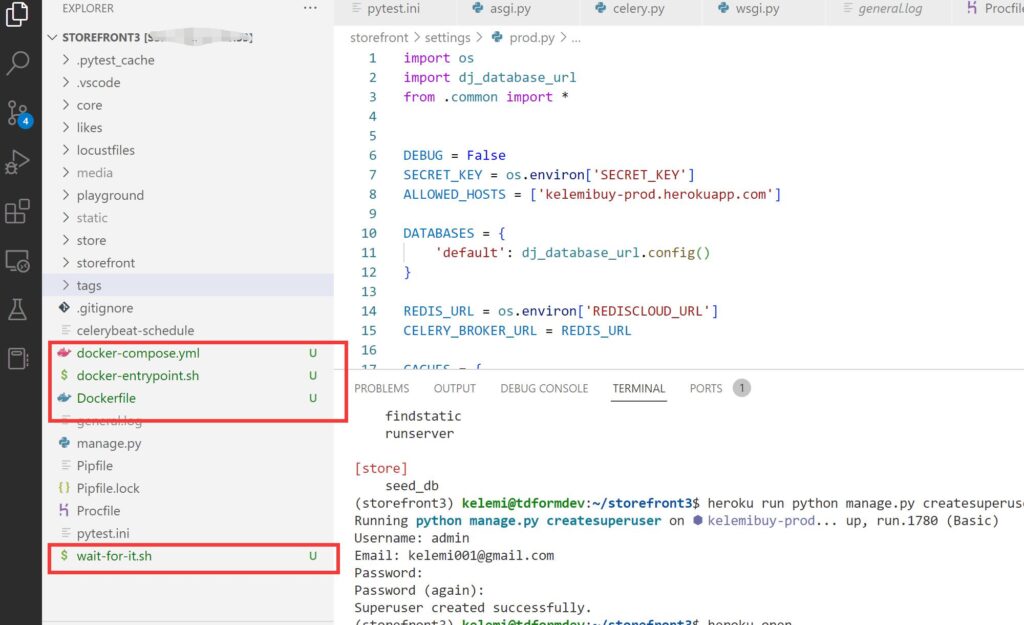
我们查看docker-compose.yml。
version: '3.9'services:web:build: .command: ./wait-for-it.sh mysql:3306 -- ./docker-entrypoint.shports:- 8000:8000depends_on:- redis- mysqlrestart: on-failurevolumes:- .:/appmysql:image: mysql:8.0ports:- 3306:3306restart: alwaysenvironment:- MYSQL_DATABASE=storefront3- MYSQL_ROOT_PASSWORD=MyPasswordvolumes:- mysqldata:/var/lib/mysqlredis:image: redis:6.2-alpineports:- 6379:6379restart: alwaysvolumes:- redisdata:/datasmtp4dev:image: rnwood/smtp4dev:v3ports:- 5000:80- 25:25restart: alwayscelery:build: .command: celery -A storefront worker --loglevel=infodepends_on:- redisvolumes:- .:/appcelery-beat:build: .command: celery -A storefront beat --loglevel=infodepends_on:- redisvolumes:- .:/app flower:build: .command: celery -A storefront flowerdepends_on:- web- redis- celeryenvironment:- DEBUG=1- CELERY_BROKER=redis://redis:6379/0- CELERY_BACKEND=redis://redis:6379/0ports:- 5555:5555tests:build: .command: ./wait-for-it.sh mysql:3306 -- ptwdepends_on:- redis- mysqltty: truevolumes:- .:/appvolumes:mysqldata:pgdata:redisdata:
这个文件可以定义我们在项目要用的全部服务,比如web服务用于Django, mysql用于mysql, redis用于redis等。当我们运行docker时,docker会启动各个服务,让他们在各自的容器或者说虚拟机里运行。运行的容器基于服务的名字,比如运行 mysql 服务的容器就叫mysql, 运行redis的容器就叫redis,等等。另外,每个服务都可以清晰地定义版本,比如mysql是8.0,这样就能保证团队在任何机器运行的都是一样的版本而不会出现意外。同样的,我们也可以确保正式环境与开发环境一致。
使用容器的话,我们需要修改dev.py的相关服务器的配置,之前使用本机IP,现在要改成docker的具体容器了。
另外Django使用Docker运行,之前的DEBUG_TOOLBAR消失了,我们需要做些破解修改。设置SHOW_TOOLBAR_CALLBACK为一个lambda函数,该函数始终返回True,如果不用lambda函数的话,需要另外定义一个返回True的函数,然后将该函数赋给SHOW_TOOLBAR_CALLBACK。
DATABASES = {'default': {...'HOST': 'mysql',...}}CELERY_BROKER_URL = 'redis://redis:6379/1'CACHES = {"default": {..."LOCATION": "redis://redis:6379/2",...}}EMAIL_HOST = 'smtp4dev'...DEBUG_TOOLBAR_CONFIG = {'SHOW_TOOLBAR_CALLBACK': lambda request: True}
然后我们停止原先的mysql,redis, celery等。因为我们启动Docker可能会与之前的产生端口冲突。
然后我们启动docker compose。作为最佳实践,需要加上 –build,确保在docker的web容器总能得到最新的代码。另外我们的docker-compose.yml里要运行2个sh文件,如果在linux中的话,确保这两个sh文件有执行权限。
docker compose up –build
当构建完成后(需要较长时间),我们能在同一个窗口看到各个应用发过来的消息,显然这些消息太多了。我们按【Ctrl + C】停掉docker compose,并重新构建,这一次我们加上 -d 参数,表示这些服务在后台运行。
docker compose up -d –build
这样我们就不会被无关的信息干扰到,如果需要查看具体的服务日志,比如要查看web的日志,我们就用命令单独查看
docker compose logs web
再打开一个终端窗口查看一个tests应用。我们发现测试都通过了。
docker compose logs tests
下次我们修改代码需要测试时,又需要打开窗口运行这个命令有点不方便。比较好的方法是加上 -f 参数实时查看。这样我们把这个窗口放在另一个显示器中,一边编码一边就能看到测试结果了。
docker compose logs -f tests
现在我们打开浏览器访问 https://127.0.0.1:8000,就能看到我们的网站了,浏览相关端点比如 /store/products,发现数据还是没有,我们需要填充数据,我们要进到我们的web服务容器里执行命令,先进行web容器的bash看看:
docker compose run web bash
然后我们就可以输入相关linux指令了,比如 ls 查看项目文件等。当然我们主要就是为执行seed_db命令,可以 exit 退出 web 容器,再执行:
docker compose run web python manage.py seed_db
等执行完毕,我们就填充了数据库,然后再访问网站相关端点,确认已有数据。
当我们需要运行其他 docker compose 的应用要停掉时,我们可以简单地输入命令即可。
docker compose down
小结
本文介绍了Django项目的部署过程,以及如何将Django项目进行容器化。容器化部分我们假设您已有Docker相关知识和经验,如果觉得有点困难,建议先学习了Docker再来。
本文是《掌握Django》系列的完结篇,感谢一路关注的朋友,咱们下一系列再见。