
本文介绍Django 对象数据库映射的有关知识,包括管理器与查询集,以及数据检索、数据过滤、Q对象、F对象、排序、限制结果、选择字段、延迟字段等内容。
Django ORM
对象与关系型数据库的映射,称为ORM。
在Django中使用ORM,可以:
- 减少代码的复杂性。
- 使代码易于理解。
- 节省时间。
前面介绍的Django的Migrate是Django ORM的一部分,本节我们继续深入。
重置数据库
为了与后续章节介绍的一致,建议下载附件,我们都从一致的地方开始。
附件地址:
https://box.zjenergy.com.cn/l/Y0TMvl
解压后,我们看到有个storefront文件夹和seed.sql文件,用vscode打开storefront文件夹。
找到settings.py,查找DATABASES节,修改成实际的mysql用户密码等配置信息。
执行:pipenv install
安装所有依赖项。
用DataGrip打开MySQL,删除storefront数据库。
再打开一个Query Console,键入SQL语句:
CREATE DATABASE storefront;
执行迁移:
python manage.py migrate
确认mysql数据库已生成了相关数据表。
关闭DataGrip所有的session(底部点services–再右键localhost–close all session),然后打开一个Query Console,将附件的seed.sql拖入,注意确认顶部数据库是storefront,选中所有的语句(command+a),然后点执行按钮。
检查我们的几个表如要store_customer、store_product、store_order、store_orderitem都已填充了数据了。
python manage.py runserver
确认正常。
管理器与查询集
键入一些代码:playgroud–views.py:
def say_hello(request):
Product.objects.all()
每一个模型都有一个管理器objects,这类似有很多功能按钮的遥控器,用来与数据库对接,除了all()方法,还有filter(),get()等等。
管理器的大部分方法,比如all()都返回一个查询集。
运行all()方法不会从数据库获取数据及返回 products 这样的对象列表。
query_set = Product.objects.all()
query_set是一个查询集,它封装了查询的对象,但它不会生成SQL语句发往数据库执行。
在某些时间点,django将评估查询集并生成正确的SQL语句发往数据库,主要是以下几种情况:
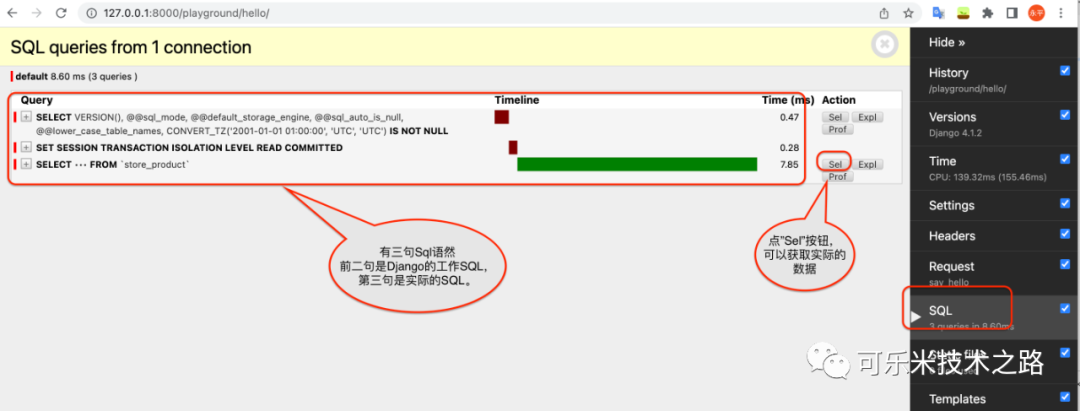
- 当我们迭代查询集时。for product in query_set: print(product)键入代码保存,刷新页面,在网页右侧调试栏–SQL,可以看到实际发往数据库的SQL。具体如图。
- 将查询集转换成列表时。list(query_set)
- 查询集切片查询时,比如取前5个数据。query_set[0:5]
所以,查询集是惰性的。那为什么在调用all()等方法时,不直接向数据库获取数据呢?
原因是:通过查询集可以组成更复杂的查询,比如:
query_set = Product.objects.all()
query_set.filter(XXX=XXX).filter(XXX=XXX).order_by(XXX)….
我们实际只需要很小的一个子集,如果all()直接返回,内存将有大量的对象,这是很浪费的。
有些方法是直接执行数据库SQL语句返回数据的,比如count(),很明显,不会再有围绕这个结果构建更复杂的语句了。
Product.objects.count()
数据检索
前面提到的all()用以取得全部对象,get方法则用来取得单个对象。
product = Product.objects.get(id=1)
id=1 也可以用 pk=1 代替。
pk表示主键,Django会自动查找主键并比较检索。
get方法返回空的话将抛出异常,需要捕捉,如下:
…
from django.core.exceptions import ObjectDoesNotExist
…
try:
product = Product.objects.get(pk=0)
except ObjectDoesNotExist:
pass
…
这种方法比较笨重,每次调用 get 都需要try…catch,可以改成:
product = Product.objects.filter(pk=0).first()
这样即使找不到对象也不会出错,而是返回null。
exists = Product.objects.filter(pk=0).exists()
exists方法返回布尔值,检测是否存在。
过滤对象
过滤用filter方法。
query_set = Product.objects.filter(unit_price=20)
表示过滤出所有价格为20 的商品。
但不能用unit_prick>20,如:
query_set = Product.objects.filter(unit_price>20)
因为 unit_price>20是表达式,结果是布尔值,作为参数传给filter是出错的。filter方法期望得到的参数是(XXX=XXX)。
为了解决大于小于过滤的问题,Django用字段后加两个下划线__再加逻辑查找类型的格式,比如查找价格大于20的:
query_set = Product.objects.filter(unit_price__gt=20)
通过谷歌查找 “queryset api”—>Field lookups ,可以查到有很多方法,如:…filter(unit_price__range=(20,30)),表示价格在20和30之间的符合记录。
双下划线也可以查找到关系,比如外键,一对多、一对一、多对多都可以。
queryset = Product.objects.filter(collection__id__range=(1,3))
这=collectiong是Product的关系,这里返回的查询集是collection的IDd在1-3范围的Product对象。当然不仅是ID,关系collection的其他字段也都是支持的。
为了直观,我们修改下hello.html加入一些查看代码:
…
<ul>
{% for product in products %}
<li>
{{ product.title }}
</li>
{% endfor %}
</ul>
…
playground–>views.py的say_hello中传递的字典也加入products。
def say_hello(request):
queryset = Product.objects.filter(collection__id__range=(1, 3))
return render(request, ‘hello.html’, {
‘name’: ‘kelemi’,
‘products’: list(queryset)
})
前面是数字的过滤,下面我们来看看涉及字符串的过滤查询。
Product.objects.filter(title__contains=’coffee’)
包含用 __contains,但我们发现页面未显示找到相关结果,原因是过滤是大小写敏感的。如果想忽略大小写,加上 i 即可。
Product.object.filter(title__icontains=’coffee’)
对于字符串,除了contains,还有
- __startswith,以什么开头
- __endswith,以什么结尾
再看看日期过滤。
日期过滤有一堆参数:
Product.objects.filter(last_update__year=2022)
除了__year,还有__month,__day以及分、秒等。
也可以直接用日期值进行比较,__date
Product.objects.filter(last_update__date=datetime.date(2022,8,22))
还有一个可以检查是否是null
Product.objects.filter(description__isnull=True)
复杂查询使用Q对象
我们看一下这个:
queryset = Product.objects.filter(inventory__lt=10,unit_price__lt=20)
这个过滤语句用了多关键字参数。当然也可以改造成多filter链式语句:
queryset = Product.objects.filter(inventory__lt=10).filter(unit_price__lt=20)
我们看到,这些都是 and 运算 组合语句,如果我们要用 or运算,就需要用到Q对象。
…
from django.db.models import Q
…
def say_hello(request):
queryset = Product.objects.filter(
Q(inventory__lt=10) | Q(unit_price__lt=20)
)
Q是队列的缩写,需要导入Q类:from django.db.models import Q
上面例子每个Q类之间用 | 分隔,表示 或 。
也可以用 & 、~ 等表示而且、非。
比如:
…filter(Q(inventory__lt=10)&~Q(unit_price__lt=20))
表示过滤库存小于10而且价格不小于20的记录。
引用字段使用F对象
有某些查询中,可能需要比较两个字段。比如我们要查询Product中的inventory=unit_price的记录,该如何做呢?用F对象!
…
from django.db.models import F
…
Product.objects.filter(inventory=F(‘unit_price’))
…
F对象也可以引用其他对象中的字段,比如:
Product.objects.filter(inventory=F(‘collection__id’))
查找Product中 invenroty等于 Collection的id的记录。
排序
排序用的是order_by方法,如:
queryset = Product.objects.order_by(‘title’)
表示按title升序排列
queryset = Product.objects.order_by(‘-title’)
表示按title降序排列。
queryset = Product.objects.order_by(‘unit_price’,’-title’)
可以进行多字段排序。
django的查询集也有一个反转方法 reverse(),它把各排序字段都作相反处理。
queryset = Product.objects.order_by(‘unit_price’,’-title’).reverse()
加了reverse()方法,实际排序字段变成了 …order_by(‘-unit_price’,’title’)
可以搜索queryset API 查所有方法。
有时候只需取单个元素,可以:
product = Product.objects.order_by(‘unit_price’)[0]
取前后单个记录也可以用earliest 和 latest 方法。earliest()方法将参数的字段按升序排列并只取第1个;latest()方法则将字段按降序排列并取1个记录。
product = Product.objects.earliest(‘unit_price’)
product = Product.objects.latest(‘unit_price’)
限制结果
queryset = Product.objects.all()[0:5]
列表切片,取前5个。
queryset = Product.objects.all()[5:10]
第二页,每页5个记录。
选择字段查询
前面的查询集都返回记录的所有字段,有时候只需返回某几个字段就好,可以使用 values()方法。
queryset = Product.objects.values(‘id’,’title’)
也可以查询关系对象的字段
queryset = Product.objects.values(‘id’,’title’,’collection__title’)
用values方法得到的是一堆字典对象,像这样:
{ ‘id’:1, ‘title’:’XXX’, ‘collection__title’:’XXX’ }
…
…
另外还有一个选择字段查询的方法是 values_list,该方法将得到一堆元组:
queryset = Product.objects.values_list(‘id’, ‘title’, ‘collection__title’)
结果是:
( 1, ‘XXX’, ‘XXX’ )
…
…
小练习
做个小练习,对前面介绍内容做个回顾。
要求:选择已在订单里的产品,并且按标题排序。
答:
queryset = Product.objects
.filter(id__in=OrderItem.objects.values(‘product__id’).distinct())
.order_by(‘title’)
注意 distinct() 是为了保留单个id。
延迟字段
对应 values方法,有 only方法。
Product.objects.only(‘id’, ‘title’)
only 与 values 的区别是:
only 获取类的实例,而 values 获得的是一堆字典对象。
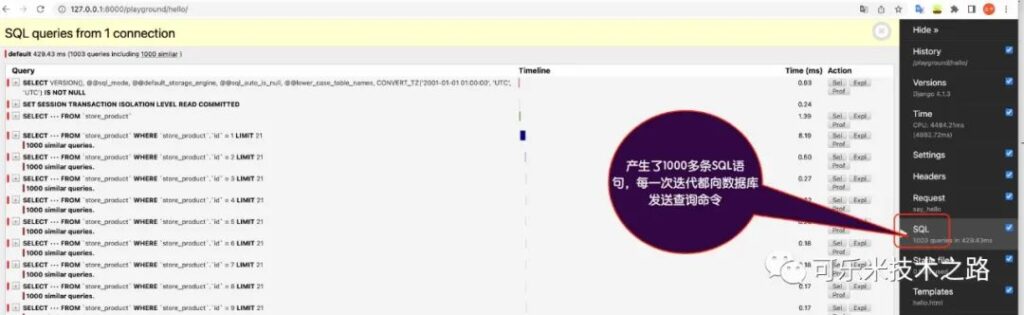
使用 only 方法要非常小心,如果不确定获取哪些字段,将会产生大量的的查询。比如:
queryset = Product.objects.only(‘id’, ‘title’)
再调用,比如类似以下的迭代获取原未列出的字段 unit_price:
for product in list(queryset):
product.unit_price
由于之前只取字段 id和title,现在要使用 unit_price,每一次迭代都会产生SQL语句访问数据库,严重影响性能。我们来实验一下:
修改 hello.html,添加红色部分显示unit_price:
…
<li> {{ product.title }} $ {{ product.unit_price }} </li>
…
我们刷新页面:http://127.0.0.1:8000/playground/hello/
发现有些卡住,因为查询产生了1000多条SQL语句。
而values方法则不会有这个问题,如果不存在,直接返回空。
values返回的是字典,不会产生SQL语句向数据库查询。
与only方法相反的是defer方法。
比如确定用不到description,可以用defer排除掉。
Product.objects.defer(‘description’)
这样会获得除description之外的其他字段。
同样的,需要小心,如果后面需要用到 description 的话,也会向数据库发送查询命令,尤其在迭代中,将严重影响性能。
小结
本文介绍了Django ORM相关的管理器与查询集,以及数据检索、数据过滤、Q对象、F对象、排序、限制结果、选择字段、延迟字段等内容,下一篇继续介绍 Django ORM的相关知识。