
给你几张猫和狗的图片,你能一眼认出哪些是狗哪些是猫,但如果让计算机程序来识别会怎么样?图片的光线,猫狗的角度、位置不同,毛发的状态形状不同,如果按传统的开发方法,通过线条、轮廓等方法识别的话会很复杂,甚至是不可能的。
这就是机器学习要解决的问题。
机器学习用途很广泛,比如自动驾驶、机器人、语言处理、股市趋势、天气以及游戏等。
本系列的最后一篇就来浅尝下机器学习。
机器学习的步骤
- 导入数据。比如CSV文件或数据库。
- 清理数据。删除重复的、无关的数据,要保持数据良好干净。
- 将数据分为两个集合:训练和测试。比如我们有1000张猫🐱狗🐶的图片,我们拿出80%用来训练,20%用来测试。
- 创建模型。选择一种算法,神经网络,决策树等。好消息是现在库很多,本节我们选择的库是scikit-learn。
- 训练模型。
- 作出预测。一般一开始是不准确的。
- 评估与改进。逐步进行微调或修改算法。
库和工具
用到的库:
numpy,数组
pandas,二维表格
matplotlib,绘图
scikit-learn,机器学习库
工具:
Jupyter
实际上也可以使用vscode等环境,但检查数据不会太方便。比如有几十列几十行的数据用Jupyter更方便。
可以使用anaconda 平台安装Jupyter。
访问:anaconda.com下载并安装。安装完成后,点击运行:
Jupyter Notebook(anaconda3)
会启动服务器,同时打开网址:http://localhost:8888/tree
在该网页上导航到桌面,New-Python 3(ipykernel)
点击名字修改成Hello World,可以看到桌面创建了一个文件:
HelloWorld.ipynb
在Jupyter网页输入命令 print(“Hello World”) ,运行后可以直接看到输出。

导入数据集
准备从kaggle.com下载示例数据。
先注册,搜索video game sales,下载压缩文件,得到vgsales.csv文件。
在Jupyter中键入代码:
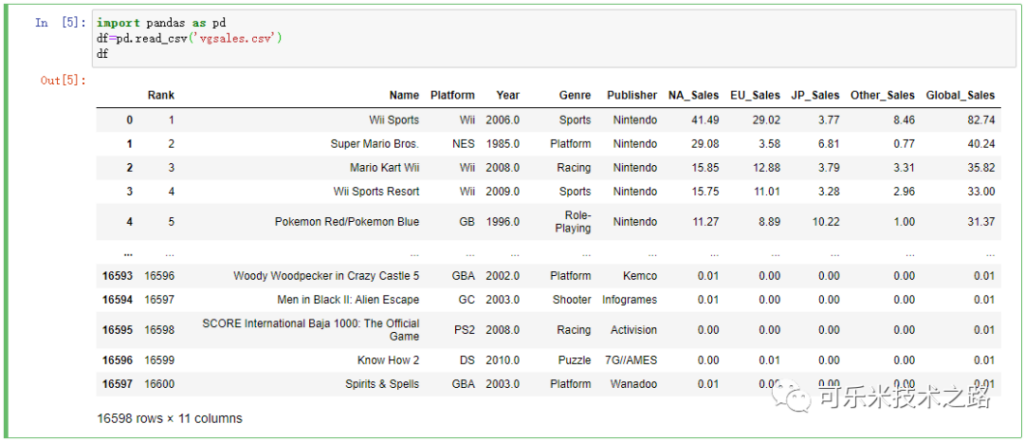
import pandas as pddf=pd.read_csv('vgsales.csv')df
df 查看数据
另起一行,输入:
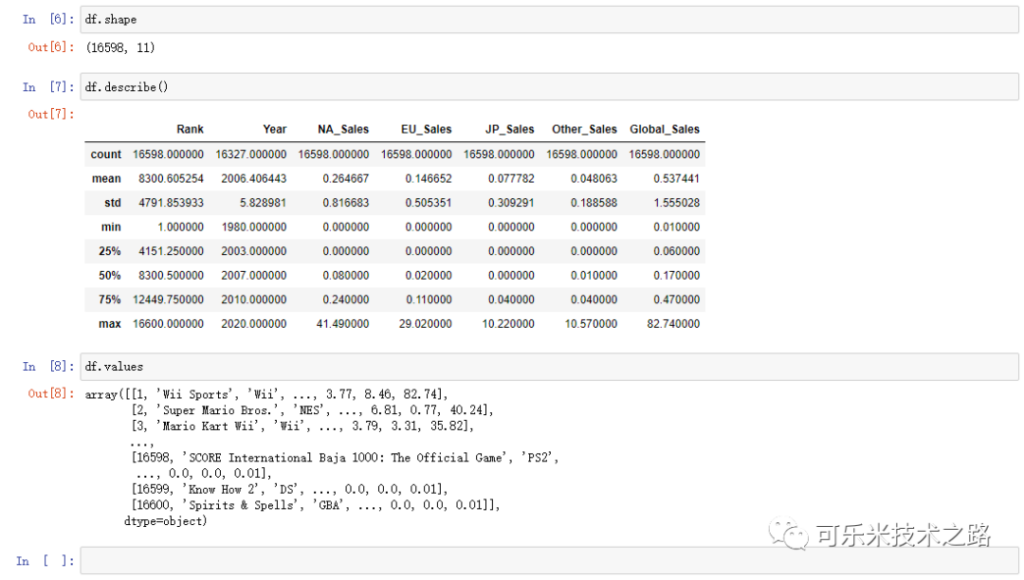
df.shape
重到行列的数量
df.describe()
返回每一列的情况。
df.values
返回一个二维数组
Jupyter快捷方式
有两种模式:
编辑模式,左侧显示为绿;
命令模式,左侧显示为蓝;
在命令模式下,按 h 能看到键盘的快捷方式。
a:在前面插入一行
b:在下面插入一行
dd:删除一行
运行只能针对特定行。
df. 再按 Tab 键显示提示。
在具体的方法上,按Shift+Tab键能显示方法的相关说明
Ctrl+/ :注释。
一个实际例子演示
建立一个模型,通过个人资料预测个人的音乐喜好,比如爵士、嘻哈,以便增加销量。
假设我们有一个music.csv文件,将它放在HelloWorld.ipynb所在的目录下。
键入代码查看下数据:
import pandas as pdmusic_data = pd.read_csv("music.csv")music_data
原始数据如下:
| age | gender | genre | |
|---|---|---|---|
| 0 | 20 | 1 | HipHop |
| 1 | 23 | 1 | HipHop |
| 2 | 25 | 1 | HipHop |
| 3 | 26 | 1 | Jazz |
| 4 | 29 | 1 | Jazz |
| 5 | 30 | 1 | Jazz |
| 6 | 31 | 1 | Classical |
| 7 | 33 | 1 | Classical |
| 8 | 37 | 1 | Classical |
| 9 | 20 | 0 | Dance |
| 10 | 21 | 0 | Dance |
| 11 | 25 | 0 | Dance |
| 12 | 26 | 0 | Acoustic |
| 13 | 27 | 0 | Acoustic |
| 14 | 30 | 0 | Acoustic |
| 15 | 31 | 0 | Classical |
| 16 | 34 | 0 | Classical |
| 17 | 35 | 0 | Classical |
一共有三列,分别是年龄、性别和喜好的音乐风格。
目前这个数据没有重复行,也没有空值,暂时无需进行清理。
我们需要将这个数据分成两个集合:输入和输出。
输入包括年龄和性别,输出是喜好的音乐风格。
现在的问题是:
21岁的男性会喜欢什么音乐风格?
注意原始数据里是没有21岁的男性的。如何实现?
键入代码:
X = music_data.drop(columns=['genre'])# 输入按照惯例使用大写Xy = music_data['genre']# 输出按照惯例用小写y表示
再来训练模型并作出预测:
from sklearn.tree import DecisionTreeClassifier# 用简单的决策树,其中sklearn是scikit-learn的一个包 model = DecisionTreeClassifier()model.fit(X,y)# 训练模型predictions=model.predict([[21,1],[22,0]])# 让模型作出预测,[21,1]表示是21岁男性,[22,0]表示22岁女性# 这两个在原数据是没有的# 我们期望21岁男性喜欢HipHop,而22岁女性喜欢Dancepredictions# 预测输出也与期望是一致的# array(['HipHop', 'Dance'], dtype=object)
计算准确性
一般情况下,70%-80%的数据用于训练,20%-30%的数据用于测试。
前面我们的例子是全部用来训练,测试的2个用例也不是原始数据。
下面我们来拆分一下。
代码:
from sklearn.model_selection import train_test_split# 用于轻松分离训练测试集from sklearn.metrics import accuracy_scoreX_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2)# 测试数据占比20%,返回的元组拆分成4个变量,model.fit(X_train,y_train)# 传递数据给模型训练predictions=model.predict(X_test)score = accuracy_score(y_test,predictions)# 测试准确率score# 输出准确率
多次运行会得到不同的结果,因为会随机选择不同的训练集和测试集。
tip:
多次运行可以按Ctrl+Enter,避免每运行一次就生成一行新单元格
另外,如果将测试数据改成0.8,准确率会直线下降,可见训练数据越多越准确。并且数据也要干净,重复和空的值会影响准确性。
模型持久化
训练了一个模型,当然希望保存下来,通过joblib模块可以实现模型的持久化。
import joblib...model.fit(X,y)# 训练模型joblib.dump(model,'music-recommender.joblib')# 将训练的模型保存下来,生成music-recommentder.joblibmodel = joblib.load("music-recommender.joblib")# 下次就可以将模型加载回来
决策树可视化
直接看代码:
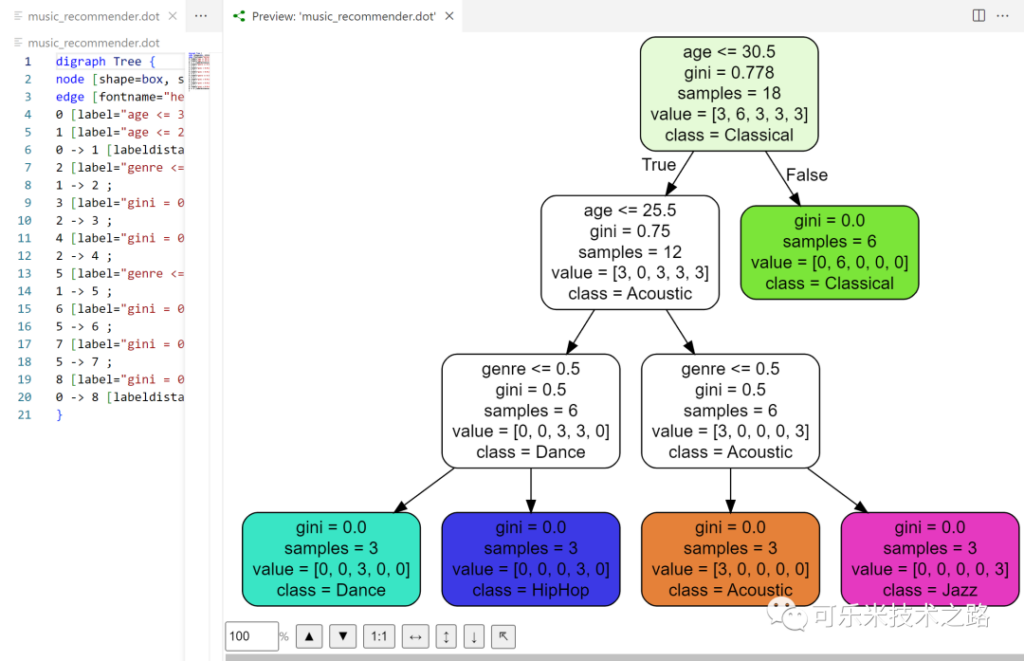
import pandas as pdfrom sklearn.tree import DecisionTreeClassifierfrom sklearn import tree music_data = pd.read_csv("music.csv")X = music_data.drop(columns=['genre'])y = music_data['genre']model = DecisionTreeClassifier()model.fit(X,y)# 以上代码是为了简化训练模型tree.export_graphviz(model,"music_recommender.dot",feature_names=['age','gender'],class_names=sorted(y.unique()),label="all",rounded=True,filled=True)
上面代码生成了 music_recommender.dot文件。
用VSCode打开该文件,也可以直接拖到vscode中。
再搜索dot安装vscode的“Graphviz (dot) language support for Visual Studio Code”插件。
打开music_recommender.dot文件,再点右上角的“Open Preview in the side”,将看到决策树的可视化图形。
结束语
完全掌握Python系列写完了,感谢一直关注的朋友们,感谢Mosh Hamedani。写一个完整系列对自己而言就是一个重新梳理知识的过程,当然更希望这个系列能帮助到想系统学习Python的朋友们。